Biometrics are booming—especially ocular and facial scans—but their potential for error and abuse concerns scientists, as well as the person being scanned.
Our security, privacy, and freedom are at stake.
That’s why experts are analyzing the enormous volume of ocular databases to help researchers match their research goals with the best, most accurate systems. Industry giants like Google and Facebook are banking on huge advancements in biometrics tech to avoid the pitfalls of faulty algorithms.
“When developing different systems based on biometric traits, experiments need to be conducted to validate the uniqueness, robustness, and feasibility of a particular trait. There are several public databases containing ocular biometric traits for researchers to experiment with,” say the authors of “Experiments with Ocular Biometric Datasets: A Practitioner’s Guideline.”
There are dozens of physical features and behaviors that can be scanned for identification and research purposes. Biometrics that use ocular images are one of the best because they’re easy to use, and the databases contain some of the largest image collections in existence.
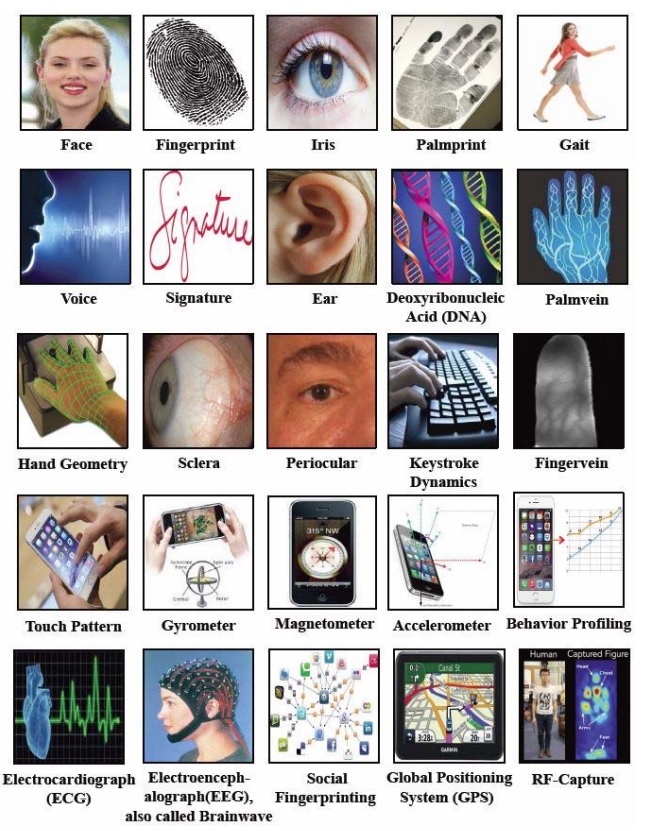
Examples of characteristics that have been proposed and used for person recognition.
Still, the questionable accuracy metrics of ocular systems have researchers worried. They insist that efforts to build better systems must forge ahead. The applications for eye biometrics range from international border crossings to smart-device unlocking.
Ocular databases “are a vital ingredient of ongoing ocular biometrics research as they are needed in system and algorithm development, when creating a platform to be used for comparing the work of different research groups, and when introducing new challenges to the research and industry communities,” say the authors.
The authors review a number of ocular databases and discuss the design, parameters, and differences among these databases—and how they can be used for a variety of experiments. The authors of this research are Zahid Akhtar of the University of Quebec, Gautam Kumar and Sambit Bakshi of the National Institute of Technology in Rourkela, and Hugo Proenca of the University of Beira Interior.
How ocular biometrics works
Ocular biometrics—which recognizes an individual by means of an iris, retinal, scleral, periocular, or eye movement scan—is gaining popularity over other methods because of its easy-to-use massive research databases and image variations.
The table below shows biometric traits present in human faces along with the advantages and disadvantages of using them.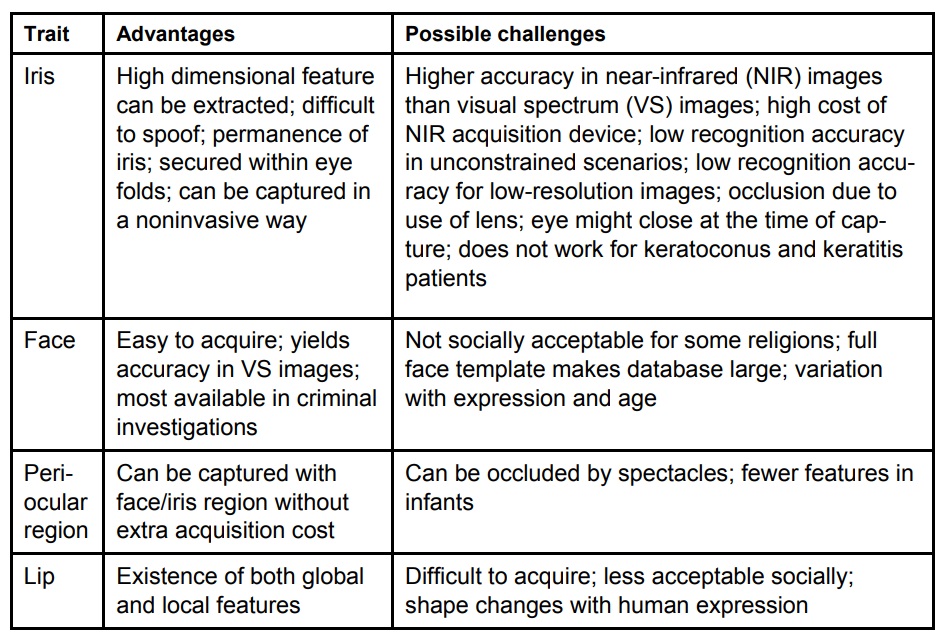
Below are sample images from a few of the face, iris, and periocular databases studied by the authors.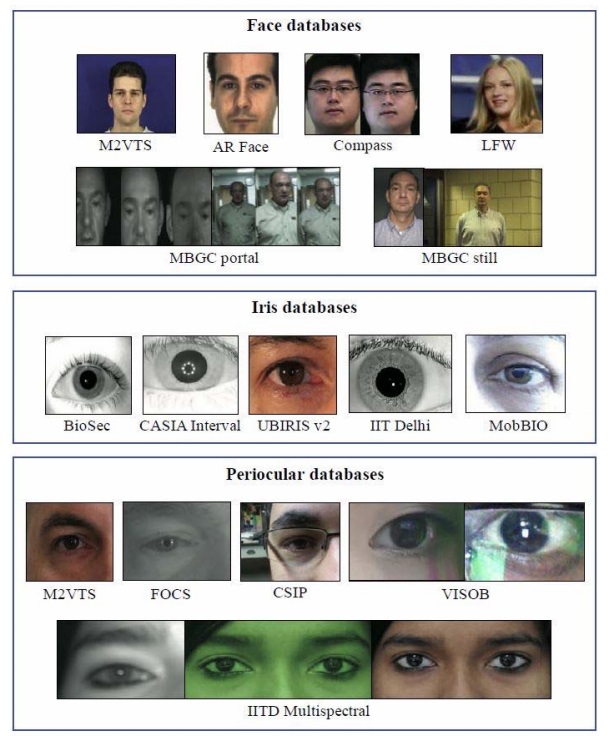
The authors analyzed the images in the databases for resolution, color, clarity, and metadata. The databases contain a mixture of images that are staged and taken “in the wild,” which can be used to test a system’s robustness.
The largest ocular databases in the world
The researchers gathered together dozens of ocular databases created and maintained by research labs all over the world.
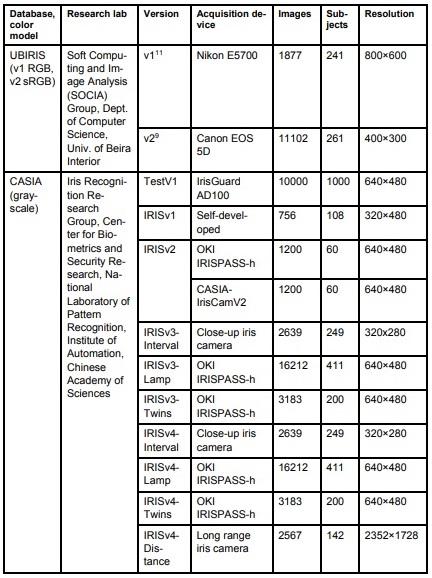
Below is a table of existing iris databases created by their corresponding research labs. For each database, the authors examined and documented the color model, acquisition device (e.g., camera model), number of images, number of subjects, and image resolution.
Below is a table of existing international face databases, which the authors analyzed for similar data.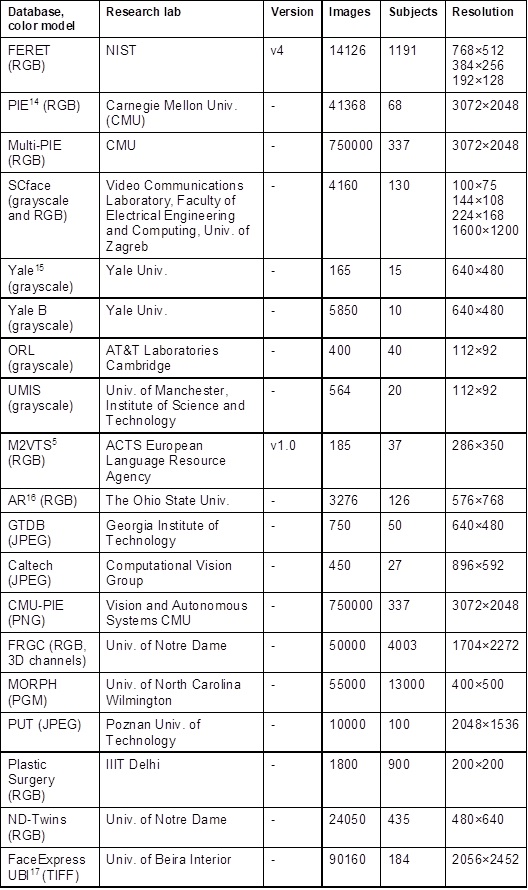
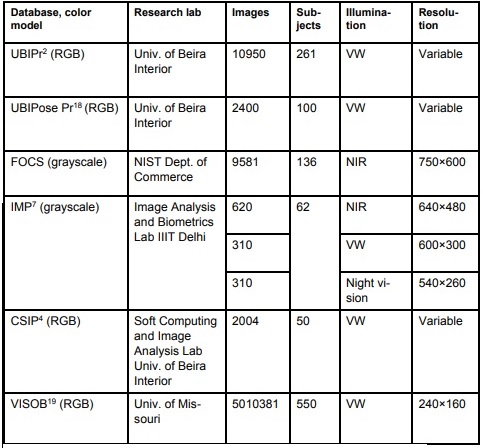
Then there are the existing international periocular databases (below), which the authors analyzed for number of images, number of subjects, illumination (visual spectrum or near infrared spectrum), and resolution.
Selecting a database for experimentation
Databases are packed with images that can meet one or more research criteria depending on the ocular system being developed.
If the system is an outdoor surveillance system, one should choose a video database such as M2VTS or CMU-H. For indoor applications, the authors recommend BioID. If researchers want multiple images of subjects wearing contacts and eyeglasses, something that can make iris scans unreliable, the Labeled Face in the Wild (LFW) database can be useful.
Another criteria is how much the images replicate real-world situations.
“M2VTS5 (which has 1,180 recordings of 295 subjects acquired over a period of four months) attracted many researchers, facilitating evaluation of many algorithms in a setup very close to real-world settings,” the authors say.
Since periocular systems are sparse, the authors encourage researchers to use images from iris databases for obtaining periocular data.
“Few databases for the periocular region such as VISOB (Visible Light Mobile Ocular Biometric) are available in the public domain. As iris databases contain the eye and its immediate vicinity including eyelashes, eyelids, and nearby skin area and eyebrows, these can be used as periocular features,” the authors say.
The value of ocular database research and evaluation
As the number of publicly-available ocular databases grows, researchers are finding it increasingly difficult to navigate the choices.
“We provided guidelines for researchers and product developers to focus on choosing the right database and evaluating ocular biometrics algorithms and systems. We hope that following these guidelines will enhance the likelihood of the results obtained in a laboratory being generalized to operational scenarios,” the authors say.
Research related to biometrics in the Computer Society Digital Library: